
Neste artigo, discutiremos algumas alternativas de malha de rede de back-end de cluster de IA e mostraremos alguns exemplos de designs do mundo real. Nosso objetivo não é defender uma seleção específica, mas sim destacar algumas compensações para que o leitor se sinta confortável com os itens que valem a pena considerar ao projetar esses tipos de tecidos. No desenho do cluster de amostra acima, o rack do meio representa esse local em uma unidade de escala típica (chamada de unidade de escala ou SU). Eles são dimensionados para aumentar o tamanho do cluster.
Considerações sobre o componente de rede em um cluster de treinamento de IA
Para entender as necessidades de tráfego de cluster de back-end de IA, primeiro teremos uma breve visão geral do processo que o treinamento desses modelos grandes segue. O processo geral segue uma distribuição de um subconjunto de grandes modelos de linguagem (LLMs) e dados a serem treinados em um cluster de sistemas. Esse processo de paralelização envolve mecanismos para analisar o conjunto de dados, (o Tensor ou matriz n-dimensional de parâmetros) a serem calculados, estabelecer um pipeline de cálculos e outros.
Grupos de aceleradores em um determinado cluster trabalham juntos no subconjunto que um gerenciador de recursos atribuiu a eles. Um gerenciador de recursos comum usado por quase metade dos supercomputadores do mundo é o Simple Linux Utility for Resource Management (SLURM) que define esse processo, juntamente com a localidade dos recursos (ou seja, um método comum é atribuir o acelerador "classificação local" em cada host para estar a apenas um estágio de silício de distância - referido como um "trilho") no cluster para otimizar o processamento e as comunicações com esses aceleradores em um determinado grupo de processamento paralelo dentro do cluster geral.
Esses sistemas executarão operações intensivas de computação de derivação de tensores de matrizes esparsas extremamente grandes com base no modelo em questão e nos dados que receberam. Quando cada nodo conclui o trabalho, ele precisa trocar as informações com todos os outros sistemas envolvidos nesse esforço de trabalho paralelo (ou seja, nem todos os nodos do cluster – mas aqueles que trabalham nesse subconjunto de todo o trabalho). Esses fluxos são muito grandes e envolvem relativamente poucos pontos finais que estão trabalhando na respectiva computação paralela – e muitas vezes chamados de "fluxos de elefante".
Após a conclusão do nodo, os sistemas individuais esperam que todos os outros nodos recebam todas as saídas do sistema e usam comunicações coletivas para sincronizar e/ou executar alguma função nos dados e compartilhar informações. Esses nodos prosseguem para a próxima iteração de cálculos. Esse ciclo é executado iterativamente até que o trabalho seja concluído.
Muitos fatores entram em jogo ao considerar a otimização do tempo geral de conclusão do trabalho (JCT) no treinamento de IA. O processo iterativo de analisar os conjuntos de dados, fazer com que muitos sistemas paralelos treinem nesse subconjunto de dados e, em seguida, mesclar os resultados entre os membros do cluster e repeti-los durante o treinamento geralmente envolve milhares de sistemas e muitas horas/dias/semanas de computação. Neste artigo, vamos nos concentrar na parte do processo em que os sistemas devem se comunicar por meio de uma malha interconectada entre seus pares. Exemplos dessas comunicações incluem compartilhamento de conjuntos de dados, resultados iterativos e operações de sincronização de sobrecarga, entre muitos outros.
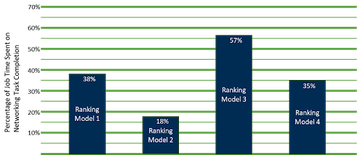
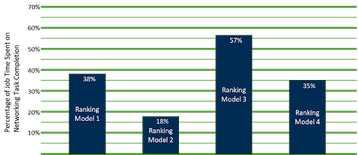
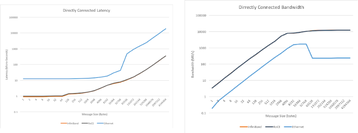
No OCP Global Summit 2022, Alexis Bjorlin, da Meta, compartilhou as informações abaixo sobre os testes realizados para quantificar os impactos do tempo gasto nesses mecanismos de comunicação, em oposição ao treinamento básico nos modelos. A Figura 1 mostra os resultados.
Embora os resultados mostrem um nível variável de impacto, a conclusão geral é que a importância de otimizar o sistema para E/S de rede pode ter um impacto significativo no JCT geral.
Malha de cluster de back-end de IA tradicional com InfiniBand
Historicamente, essa comunicação utilizou com mais frequência uma malha InfiniBand (IB), que inicialmente era ideal para mercados de computação de alto desempenho (HPC), e muitas de suas características complementavam as necessidades dessas malhas de IA. Alguns exemplos dessas otimizações incluem:
- RDMA (acesso remoto direto à memória)
- Transmissão e recepção sem perdas por meio de gerenciamento de buffer de ponta a ponta
- Prevenção de congestionamento
- Agregação de mensagens baseada em malha
RDMA
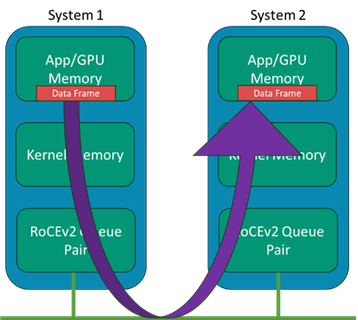
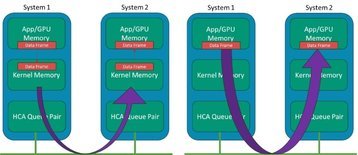
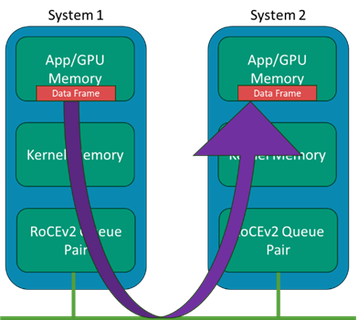
Geralmente, o conceito RDMA existe no IB há muitos anos, em que os sistemas podem ignorar as estruturas de dados e buffers do kernel e minimizar a movimentação intermediária de dados entre essas camadas em uma transmissão de dados no lado do remetente e a recepção no lado do receptor. Enquanto a transmissão de dados tradicional usa os drivers de rede e a pilha do kernel, que usam a CPU do host, o RDMA ignora essas camadas e coloca os dados diretamente da memória do aplicativo para o fio e da mesma forma do fio diretamente para a memória do aplicativo.
Em sistemas de IA modernos, a "aplicação" aponta para o espaço de memória dos sistemas GPU, de modo que a E/S do adaptador esteja ignorando a memória do kernel. Em um sistema com muitas GPUs, mas apenas algumas CPUs, não queremos que a cópia e o processamento de quadros da CPU se tornem o gargalo. A Figura 2 mostra uma ilustração do conceito com adaptadores de canal de host (HCA) IB.
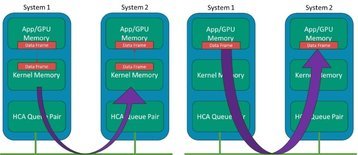
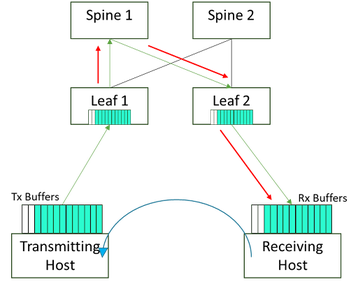
Transmissão sem perdas e baixa latência
A rede tradicional da maioria dos tipos envolve alguma suposição de que uma porcentagem dos dados está sendo perdida em trânsito devido a buffers transbordantes, pacotes que falham nas verificações de integridade devido a erros de bit e outros.
Para ajudar a mitigar o risco de estouro de buffers e perda de tráfego na malha, uma solução baseada em crédito é implementada para ajudar a pressionar de volta na direção dos remetentes de tráfego, de modo que o tráfego não possa ser encaminhado sem aprovação prévia. Esse sistema garante uma malha sem perdas que garante que os trabalhos de IA não sejam interrompidos devido a uma pequena porcentagem de perda de tráfego.
Prevenção de congestionamento
Para ajudar o tráfego a transitar pela malha e evitar os principais pontos de congestionamento, os switches IB compartilham informações sobre informações de congestionamento junto com qualquer link ou informações de interrupção do transceptor para ajustar e manter o tráfego fluindo.
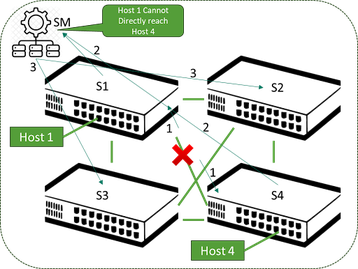
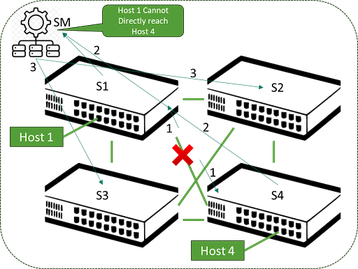
A arquitetura IB exige um item chamado "gerenciador de sub-rede" que tem a responsabilidade geral de monitorar o comportamento na malha por meio de varreduras periódicas e mensagens entre os elementos da estrutura. Por si só, haveria um risco de comportamento abaixo do ideal na contabilização de interrupções de link e nodo, mas isso é tratado por meio de roteamento adaptativo, em que o encaminhamento de pacotes também leva em consideração a profundidade da fila nas interfaces de saída.
Se estiver preenchendo com base no congestionamento, ele escolherá outro membro ECMP (Multi-Path) de custo igual para enviar os pacotes. Isso fornece um meio muito mais rápido de redirecionar o tráfego em torno de links afetados por esses eventos. Isso é chamado de roteamento adaptativo em uma malha IB, mas a desvantagem é que ele introduz a chance de chegada de pacotes fora de ordem - mas o silício HCA moderno pode corrigir isso. A Figura 3 mostra uma ilustração simples dessa situação em que nenhum roteamento adaptativo está presente.
Agregação de mensagens
Uma área importante dos sistemas de processamento paralelo é o meio de compartilhar as saídas de cada nodo dentro do sistema maior com seus pares. Embora os métodos para agregar esses resultados não sejam novos, a extensão deles para redes de IA é algo que surgiu à medida que esses sistemas cresciam.
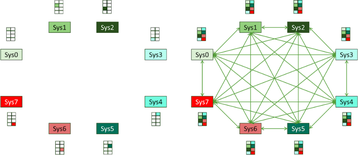
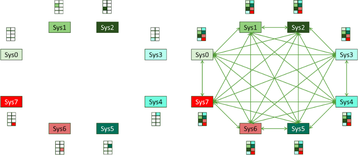
A discussão geral por trás dos métodos aqui está além do escopo deste artigo, mas tentaremos resumir os pontos essenciais com base em como isso ocorre hoje. Para ajudar a ilustrar o problema, usaremos a Figura 4.
Isso faz com que muitos nodos individuais se comuniquem na malha com muitos outros, e cada mensagem tem sua própria configuração de conexão, transferência e desmontagem nos hosts e na estrutura.
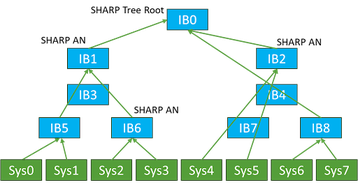
A ideia de desenvolver um método para simplificar isso por meio de alguma agregação intermediária foi adicionada à arquitetura do IB (embora o mecanismo não exija o IB).
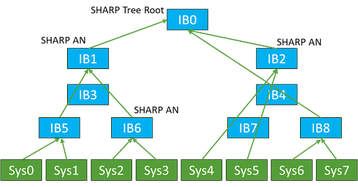
O conceito de agregação de mensagens e um meio mais eficiente de minimizar as contagens de interconexões seria cada vez mais importante à medida que a contagem de nodos fosse dimensionada para milhares e dezenas de milhares de nodos em um cluster. Os nodos intermediários que executam essa tarefa de agregação de mensagens, juntamente com as funções de transportar os próprios dados, foram concebidos e são utilizados hoje.
Ao empregar essas técnicas de redução de mensagens, o número de mensagens necessárias entre os nodos é dimensionado é muito melhor do que o N*(N-1)/2 da malha completa.
Mapeando essas necessidades no mundo das redes de cluster de back-end Ethernet
Muitos clientes das soluções de IA atuais continuam a implantar com o IB como a malha preferida para obter esses benefícios. Alguns clientes, no entanto, estão avaliando ou já usando malhas Ethernet como uma alternativa ao IB por alguns dos seguintes motivos:
- A Ethernet tem um ecossistema muito grande e aberto
- Seleção mais ampla em silício e opções de software aberto
- Crescimento da indústria com velocidades de interconexão e trajetória de crescimento
- Malhas de IA em maior escala – ainda mais com tráfego roteado
- Estabelecer segmentação de tráfego para dar suporte às necessidades de multilocação
- Experiência e ferramentas existentes na implantação, gerenciamento e observação de Ethernet
Antes de nos aprofundarmos na revisão técnica de como as tecnologias Ethernet estão sendo adaptadas para atender a muitas das necessidades que o InfiniBand resolve, primeiro mostraremos uma comparação de tráfego de alto nível entre Ethernet e IB como existe hoje da perspectiva do desempenho de E/S. Em uma malha Ethernet AI, temos uma combinação de tecnologias além da rede Ethernet tradicional para fazer essas medições de desempenho de tráfego. A Figura 6 mostra os resultados em uma variedade de tamanhos de mensagem. Esses testes foram feitos com EDR InfiniBand, e a comparação foi de 100GE.
Existem outros estudos de vários níveis de regras de acesso à publicação, mas a conclusão geral foi que, se tentarmos implantar um domínio Ethernet de uso geral, o desempenho resultante não será suficiente para as necessidades de uma rede de cluster de IA.
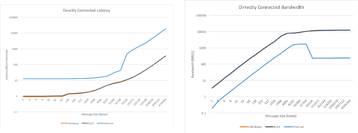
Se, em vez disso, essas infraestruturas fizerem uso de uma infraestrutura Ethernet sem perdas otimizada, o desempenho se aproximará muito do desempenho do InfiniBand do ponto de vista da largura de banda de tráfego e da latência.
A Figura 6 mostra que o desempenho bruto da E/S é consistente entre essas tecnologias. Para obter uma visão completa em um cenário prático de rede de IA, no entanto, também precisamos levar em conta as várias otimizações presentes no mundo IB, que não seriam exibidas em um gráfico de desempenho bruto. Uma lista dessas tecnologias inclui:
- Comunicações diretas de GPU para GPU
- Velocidade bruta e latência
- Comportamento sem perdas e prevenção de congestionamento
- Agregação de mensagens
- Falha de link e redirecionamento
- Segmentação de caminho
- Balanceamento de carga
Comunicações diretas de GPU para GPU
Conforme discutido anteriormente neste artigo, o InfiniBand usa o RDMA para mapear diretamente a E/S de/para o fio para a memória na GPU. No domínio Ethernet, isso foi adotado usando RDMA, mas transportado por Ethernet convergente - o que significa que essa Ethernet agora está convergindo para o tráfego de transporte que tradicionalmente estava em sua própria malha (ou seja, InfiniBand).
O RDMA foi aprimorado para oferecer mais escala e distância física, adicionando um método para rotear esse tráfego na versão dois da especificação. O resultado é comumente chamado de RoCEv2 e é onipresente nos domínios Ethernet e nas placas de interface de rede (NICs) nos sistemas. Uma ilustração está na Figura 7.
Velocidade bruta e latência
As estimativas da Dell'Oro no mercado de portas Ethernet estão à esquerda, e as portas 800GE se tornando dominantes em relação às 400GE em 2025 mostram a taxa de inovação atual em velocidade, com portas de alta velocidade sendo dominantes no DC até 2027.
À medida que analisamos mais detalhadamente os roteiros dos fabricantes de silício, vemos as portas Ethernet de 1,6 T ganhando penetração rápida em 2027. Esse ritmo de crescimento não está mostrando nenhum declínio significativo no final de 2023.
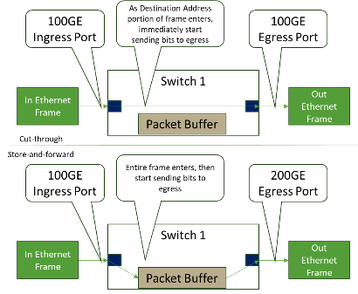
Nas redes Ethernet, definimos uma latência porta a porta para que um quadro entre, seja agendado e saia de um determinado elemento de comutação. Nesta área, um elemento Ethernet típico pode variar consideravelmente (variando de ~ 300ns a ~ 3000ns) dependendo do hardware e do que está acontecendo com o quadro à medida que transita pelo dispositivo. Em um switch Ethernet moderno com entrada de velocidade equivalente às portas de saída, o encaminhamento cut-through fornece latência muito baixa, como mostrado na Figura 8.
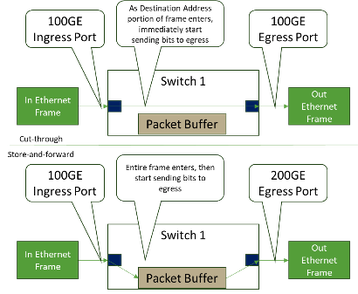
O IB pode estar na faixa de ~ 200ns a 300ns para o mesmo salto, o que significa que essa área no IB de tecido tem uma vantagem, pois esse transporte não tem a mesma gama de tipos de aplicação. Obter a latência o mais baixa possível é desejado para muitas necessidades de rede de IA.
Há também um elemento que muitos usam em discussões sobre "latência de cauda", que é a latência da última mensagem em uma rede de mensagens e é importante em clusters de IA, pois todos os nodos aguardam que todos os dados sejam atualizados antes de passar para a configuração a seguir.
Isso pode significar que os nodos estão ociosos enquanto outros aguardam as últimas mensagens, o que significa que essa é uma métrica muito importante em toda a estrutura. Esse nível de visibilidade é mais impactante do que observar a latência de um elemento de comutação, e é aqui que a indústria de Ethernet está otimizando entre os próprios elementos e os métodos para equilibrar e distribuir o tráfego no nível da malha. Nesse domínio, os muitos conjuntos de ferramentas Ethernet que existem para otimizar esses fluxos trazem uma discussão de latência para um resultado geral comparável entre essas tecnologias.
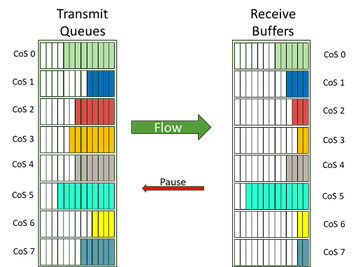
Comportamento sem perdas, prevenção de congestionamento e segmentação de caminho
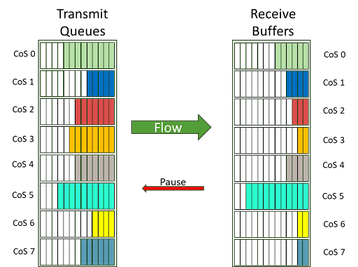
Os conceitos de habilitar o comportamento sem perdas e evitar congestionamento na Ethernet são uma discussão mais longa e além do escopo deste documento (assim como os métodos sem perdas no IB). Os ativadores individuais incluem controle de fluxo por prioridade (PFC, exemplo na Figura 9) para permitir a pausa do tráfego por classe de serviço.
Outra chave para gerenciar o congestionamento para permitir o comportamento sem perdas é mostrada na Figura 10, onde uma notificação de congestionamento explícita (ECN) é sinalizada definindo um valor de congestionamento experimentado (CE) na parte DSCP do cabeçalho IP nesses switches intermediários para permitir que o receptor informe o remetente para desacelerar para que o tráfego não seja perdido.
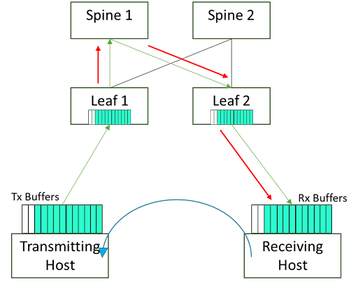
Os mecanismos para monitorar, detectar e sinalizar tudo isso são incorporados ao silício de comutação moderno e já estão presentes em uma malha de rede compatível com RoCEv2. Esses métodos também monitoram o congestionamento em determinados links e são usados como entradas para outros protocolos para controlar o tráfego em links alternativos para segmentação de caminho e balanceamento de carga eficazes (abordados abaixo).
Agregação de mensagens: na malha versus sistemas de GPU
Hoje, não há função equivalente para executar a função de agregação de mensagens no ambiente Ethernet. Para sua informação, há trabalho no grupo In-Network Collectives do Ultra Ethernet Consortium para definir vários conjuntos de funções onde essas operações coletivas podem ser executadas. O trabalho nesta especificação está previsto para um primeiro lançamento no final de 2024.
Protocolo de gateway de borda intra-DC (BGP) como um meio de aproximar o roteamento adaptativo IB e o balanceamento de carga na malha.
A Ethernet usou mecanismos de Camada 2 ao longo de sua história (Spanning Tree e outros métodos mais modernos) para garantir um caminho sem loop na malha para os hosts se comunicarem. Quando um link ou nodo é perdido, o dispositivo conectado diretamente removerá as entradas das tabelas MAC usando o caminho com falha.
Tradicionalmente, os temporizadores precisariam expirar para que os elementos na malha procurassem caminhos alternativos (roteamento estático). Juntamente com a perda de casos de link/dispositivo, o caso de congestionamento geralmente não era tratado até a introdução de PFC, ETS, DCQCN com ECN, WRED, etc., na malha Ethernet.
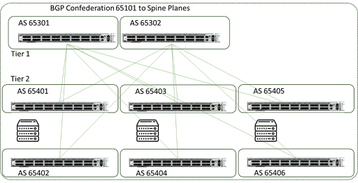
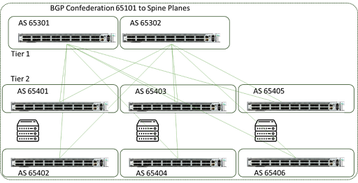
Para aprimorar a recuperação de falhas de enlace e nodo, além de se adaptar efetivamente a links congestionados, muitos usuários finais agora estão usando métodos como roteamento BGP dentro do DC para trazer ajustes mais ativos à malha de uma forma um pouco próxima do que o Roteamento Adaptativo no InfiniBand executa, dependendo se o balanceamento de carga de custo igual ou desigual é utilizado.
Esses mecanismos são muito eficazes para rastrear e ajustar padrões de tráfego e restabelecer caminhos sem interação humana. A Figura 11 mostra um exemplo da topologia (de um artigo público do Facebook).
Resumo
Muitos componentes de uma rede de cluster de IA neste artigo discutem a possibilidade de usar Ether InfiniBand ou Ethernet nesses projetos e as compensações.
Mais sobre a Supermicro

Patrocinado Fear and Loathing: AI edition
As AI reshapes industries, businesses must weigh risks against the need to innovate and stay competitive by leveraging their data and exploring AI solutions

10 best practices for CSP's to scale the data center
Considerations to create a modern data center

Patrocinado Considerations for AI factories
As AI factories that produce intelligence from existing content, new data centers must consider computing technologies available today and how to remove the heat created by these powerful servers



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}